
In short words, hashing is a process of generating a value or values from a string of text using a mathematical function. Let's see the usage of the MS SQL function HASHBYTES witch purpose is to hash values. MS SQL function HASHBYTES was introduced in MS SQL version 2005 supporting MD2, MD4, MD5, SHA, SHA1 hashing algorithms. From MS SQL server version 2012 additionally the SHA2_256, SHA2_512 algorithms were introduced. In this article we will discuss about hashing, what's new from SQL 2016 and see some usage examples.
Encryption vs Hashing
When talking about securing data, two main methodologies are used:
- encryption - Encryption is a two-way process in which a value can be decrypted through the correct decryption key. You can get the original value from the encrypted value. The process of encryption is reversible.
- hashing - Hashing is a one-way process and is used to mask data. In that process there is a minimal chance that someone could reverse the hashed value back to the original value. The attacker could try to guess the starting value in a try/fail game. Hashing can't show us the original value but can tell us exactly if the input value is the same as the stored value.
HASHBYTES
Now when we understand the basics, let's see the usage of MS SQL HASHBYTES function whose purpose is to hash values.
Syntax:
HASHBYTES ('algorithm', input)
- algorithm - hashing algorithm to be used to hash the input. Possible values are: MD2, MD4, MD5, SHA, SHA1, SHA2_256, SHA2_512
- input - specifies the input variable, column, or expression containing the data to be hashed. The input value can be one of the following data types: (n)varchar, varbinary
The function returns the data of type varbinary(8000). The resulting size of the varbinary output dependents on the used algorithm and can be from 16 to 64 bytes.
Prior to SQL Server 2016, the input value was limited to 8 000 bytes. Now the limit does not exist anymore, and you can use the (n)varchar/varbinary(max) input data. There are several techniques how to handle large data hashing prior to MS SQL 2016 but in this article, we will not discuss about them.
Starting with SQL Server 2016, all algorithms other than SHA2_256, and SHA2_512 are deprecated. They will continue to work but only the last two are recommended for usage.
Let's start with a basic usage example.
Example:
DECLARE @TestData NVARCHAR(MAX) = 'My test data'
SELECT HASHBYTES ('SHA2_512', @TestData) AS [Hash value];

The result length of hashing will depend of the algorithm used and for more complex algorithm the output is bigger. Also, more complex algorithms requires more CPU power and will take more time for calculation.
Example:
DECLARE @TestData NVARCHAR(MAX) = 'My test data'
SELECT HASHBYTES ('MD2', @TestData) AS [Hash value], DATALENGTH(HASHBYTES ('MD2', @TestData)) AS [Data lenght];
SELECT HASHBYTES ('MD4', @TestData) AS [Hash value], DATALENGTH(HASHBYTES ('MD4', @TestData)) AS [Data lenght];
SELECT HASHBYTES ('MD5', @TestData) AS [Hash value], DATALENGTH(HASHBYTES ('MD5', @TestData)) AS [Data lenght];
SELECT HASHBYTES ('SHA', @TestData) AS [Hash value], DATALENGTH(HASHBYTES ('SHA', @TestData)) AS [Data lenght];
SELECT HASHBYTES ('SHA1', @TestData) AS [Hash value], DATALENGTH(HASHBYTES ('SHA1', @TestData)) AS [Data lenght];
SELECT HASHBYTES ('SHA2_256', @TestData) AS [Hash value], DATALENGTH(HASHBYTES ('SHA2_256', @TestData)) AS [Data lenght];
SELECT HASHBYTES ('SHA2_512', @TestData) AS [Hash value], DATALENGTH(HASHBYTES ('SHA2_512', @TestData)) AS [Data lenght];
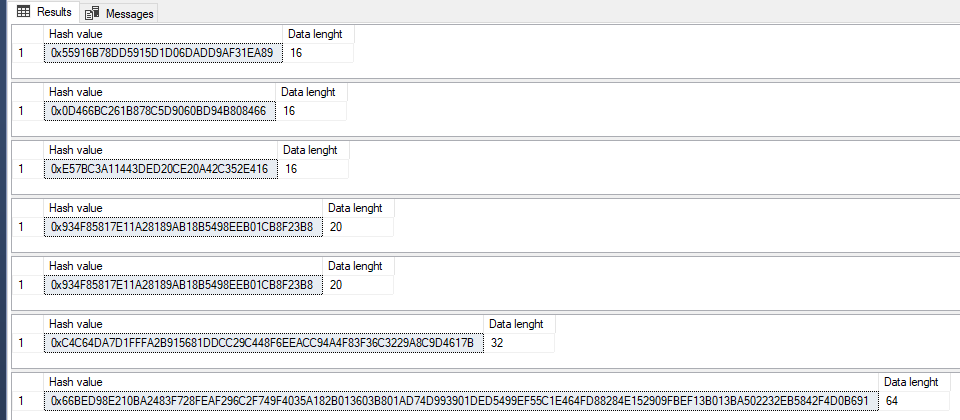
If you are not sure what is the correct hashing algorithm you should use than the correct answer depends on what's the purpose of hashing. If you need hashing just to compare two values (see later in this article) than is irrelevant and you should maybe use the fastest and the simpler one (be aware of hash collision!). If you need hashing for security issues (e.g. passwords) than is probably the best choice to use the more complex algorithm.
If you try to hash a value that takes more than 8000 bytes in older MS SQL version than 2016 an exception will be raised:
"String or binary data would be truncated"
There is a chance that two distinct inputs can result with the same result (hash "collision" or "clash"). The more powerful the hashing algorithm is, there is lower chance of a such scenario. To avoid that, usually when we create hash values we use a salt value. A salt value is a random string that is appended on the string we want to hash so for two consecutive hashing of the same value we would get a different result. This could make it harder to guess somebody password if two persons use the same password. In MS SQL Server the hash calculation doesn’t use the salt value but rather a straightforward hash value calculation is performed. That means that the same input value will always produce the same output value. We could create a user defined function and extending the HASHBYTES function to include a salt value, but this is something that depends of our business case.
Example:
DECLARE @TestData NVARCHAR(MAX) = 'My test data'
SELECT HASHBYTES ('SHA2_512', @TestData) AS [Hash value 1];
SELECT HASHBYTES ('SHA2_512', @TestData) AS [Hash value 2];

Take care that different data types return different result (e.g. varchar and nvarchar).
Example:
SELECT HASHBYTES ('SHA2_512', N'Gin tonic') AS [Hash value 1];
SELECT HASHBYTES ('SHA2_512', 'Gin tonic') AS [Hash value 2];

Also, if the data collation is different, the resulting hash could be different.
Usage of hashing
Basic usage
You can use hashing to store some sensitive data in your database. Basically as said before, hashing is used when you don't have the need to be able to decrypt (return the data in the initial state). For example you could use hashing to store user passwords in the database.
Data compare
Another handy usage of hashing is comparing tables or rows from two environments since you do not need to transfer all the data from two systems. To be able to determinate what data are changed you can just transfer hash values over network or some slow connections.
The old approach for compare two tables or rows using hashing was basically consisted of the following steps:
- cast all values to a string data type (n)varchar,
- replace null values with an empty string (ISNULL),
- put them to lower (if we don't care about lower/upper case differences),
- concatenate the fields together in string form with a delimiter,
- hash this resultant string value (3) to get a single value that represents the string value (but significantly smaller),
- compare this hash values to a different source to determinate if the values are changed or not.
You can find a lot of useful examples on the WEB, if you like I suggest you to look at the Hashing for Change Detection in SQL Server by Nigel Meakins.
Since now in MS SQL Server we have the XML and the JSON data format support and methods to convert tabular data in XML or JSON format, the procedure is now much easier.
Example:
SELECT
C.CustomerID
, HASHBYTES ('SHA2_512', (
SELECT
*
FROM
[Sales].[Invoices] I
INNER JOIN [Sales].[InvoiceLines] IL ON I.InvoiceID = IL.InvoiceID
WHERE
I.CustomerID = C.CustomerID
FOR XML AUTO)
) AS [Invoices hash]
FROM
[Sales].[Customers] C
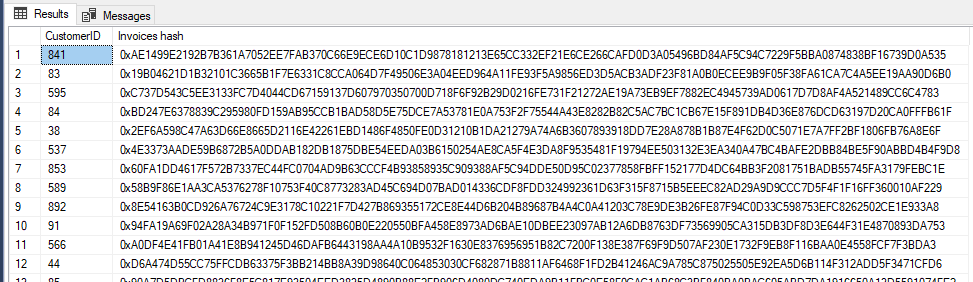
In this example we created hash values of all invoices per customer and now would be easily to compare the hashes with another system.
*MS SQL Server sample database "WideWorldImporters" can be downloaded at: https://github.com/Microsoft/sql-server-samples/releases/tag/wide-world-importers-v1.0
*You can download the complete SQL Script with all examples from the post here: SQL Script.sql (1.86 kb)