
Now when we know more about hierarchies in MS SQL Server and we overviewed existing methods for the HierarchyID data type it’s time to discuss about the benefits of using HierarchyID data type.
As told before, the usual solution how to handle hierarchy in a database was to use two columns. The first column contains the ID of the hierarchical member (in much cases also the primary, unique ID), and the other, the ID of its parent hierarchical member. From SQL Server 2008 we can use the HierarchyID data type that is a data type written in .NET and exposed in SQL Server. HierarchyID offers us some performance benefits and simplified code.
Here are the scripts to create the test tables (one without the use of the HierarchyID data type and one with).
CREATE TABLE [dbo].[Hierarchy_Std](
[ID] [int] NOT NULL,
[ReportToID] [int] NULL,
[Role] [varchar](256) NOT NULL,
[BirthDate] [date] NOT NULL,
CONSTRAINT [PK_Hierarchy_Std] PRIMARY KEY CLUSTERED ([ID] ASC)
) ON [PRIMARY];
GO
CREATE TABLE [dbo].[Hierarchy_HID](
[ID] [int] NOT NULL,
[Hierarchy] [hierarchyid] NULL,
[Role] [varchar](256) NOT NULL,
[BirthDate] [date] NOT NULL,
CONSTRAINT [PK_Hierarchy_HID] PRIMARY KEY CLUSTERED ([ID] ASC)
) ON [PRIMARY];
GO
Data storage
Now, let’s insert some test data and see the inserted data:
INSERT INTO [dbo].[Hierarchy_Std] ([ID], [ReportToID], [Role], [BirthDate])
VALUES
(1, NULL, 'Chief Executive Officer', '1969-01-29')
, (2, 1, 'Vice President of Engineering', '1971-08-01')
...
, (25, 21, 'Production Technician 3', '1983-01-07');
GO
INSERT INTO [dbo].[Hierarchy_HID] ([ID], [Hierarchy], [Role], [BirthDate])
VALUES
(1, '/', 'Chief Executive Officer', '1969-01-29')
, (2, '/1/', 'Vice President of Engineering', '1971-08-01')
...
, (25, '/5/1/1/4/', 'Production Technician 3', '1983-01-07')
GO
SELECT * FROM [dbo].[Hierarchy_Std];
SELECT * FROM [dbo].[Hierarchy_HID];
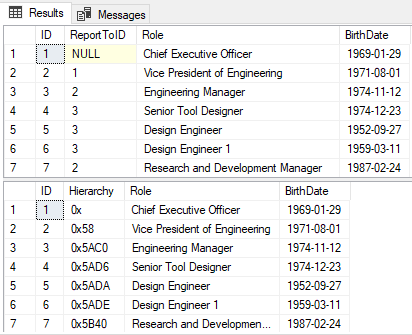
Notice that whan inserting data in the hierarchyid data type column (column [Hierarchy]) we have used human-readable strings (e.g. “/1/1/1/”). SQL Server used the method Parse() and directly try to convert these strings and store them as hexadecimal values (e.g. “/1/1/3/” -> “0x5ADE”).
The hexadecimal value makes the column extremely compact and efficient. The size of the hierarchyid column consumes less space than the solution with the int. Let’s compare the data size of the two columns.
SELECT
(SELECT SUM(DATALENGTH(ReportToID)) FROM [dbo].[Hierarchy_Std]) AS SizeOfInt
, (SELECT SUM(DATALENGTH(Hierarchy)) FROM [dbo].[Hierarchy_HID]) AS SizeOfHierarchyid;
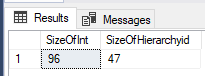
Less space used is equivalent to better performance!
Data manipulation
The second benefit of using hierarchyid data type compared to the other solution is the that the code for manipulating hierarchical data is cleaner. Let’s see one more the solution for the simple task of getting the average age for all employees in the “Production department”.
Here is the solution on the table that does not use hierarchyid data type:
;WITH CTE ([ID], [ReportToID], [Role], [BirthDate])
AS (
SELECT
A.[ID]
, A.[ReportToID]
, A.[Role]
, A.[BirthDate]
FROM
[dbo].[Hierarchy_Std] A
WHERE
ID = 19
UNION ALL
SELECT
A.[ID]
, A.[ReportToID]
, A.[Role]
, A.[BirthDate]
FROM
[dbo].[Hierarchy_Std] A
INNER JOIN CTE ON A.ReportToID = CTE.ID
)
SELECT
AVG(DATEDIFF(YEAR, C.[BirthDate], GETDATE())) AS AvarageAge
FROM
CTE C;
And, here is the solution with the hierarchyid data type used:
SELECT
AVG(DATEDIFF(YEAR, C.[BirthDate], GETDATE())) AS AvarageAge
FROM
[dbo].[Hierarchy_HID] C
WHERE
C.Hierarchy.IsDescendantOf(0x8C) = 1;
Notice the two queries. The second one is much smaller and easier to read and understand. The first example forced us to use the recursive CTE because without this getting the result would be a very difficult task to accomplish.
Performance
Let's compare the execution plans and the query statistics for the two queries.
Table 'Hierarchy_Std'. Scan count 1, logical reads 17, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 'Worktable'. Scan count 2, logical reads 43, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 114 ms.
Table 'Hierarchy_HID'. Scan count 1, logical reads 3, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 102 ms.
The first query used 114ms and the second 102ms. The first query used TempDB and the second didn’t. Also, the first had in total 60 logical reads, and the second just 3. Maybe on the first look this doesn’t look like a great improvement (especially if you look the elapsed time), but we are now talking about two tables with just 25 rows per table. Imagine if we had tables with few million rows! And very important, we didn’t use a single index until now.
Let’s compare the execution plans of the two queries:
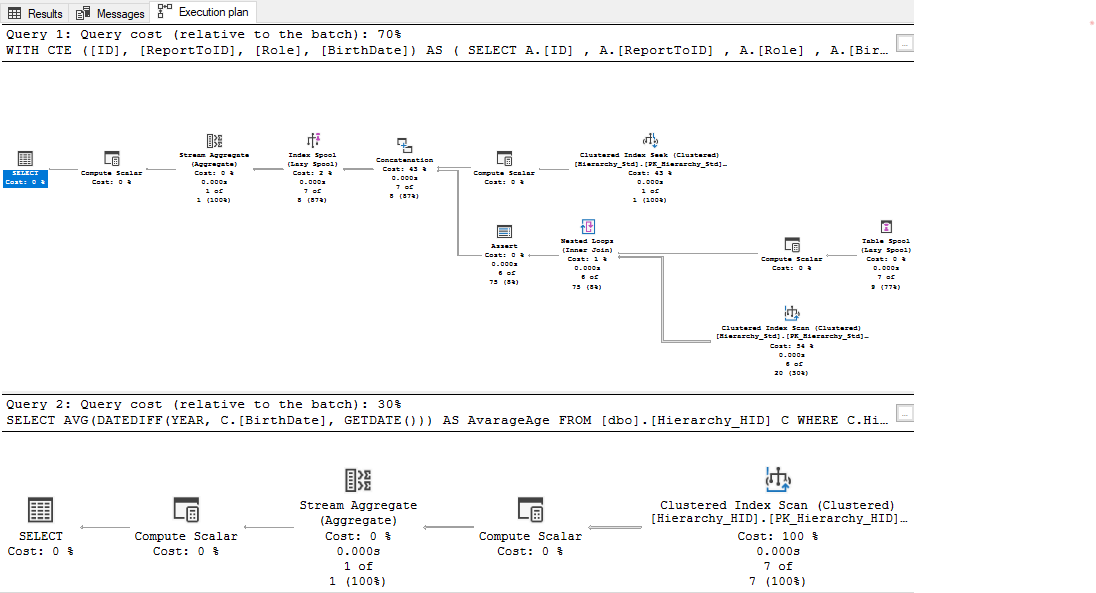
Even if we don’t analyze them in depth, we can conclude that the first is much more complicated compared to the second one 😊.
Indexing
Let’s see what we can do about indexing hierarchyid columns.
Hierarchyid doesn’t have special or dedicated index type like for example XML. To increase performance of hierarchyid columns we can use standard clustered and nonclustered indexes.
When creating indexes to improve hierarchyid columns we can use one of the two strategies:
- depth-first - descendants will be stored close to their parents,
- breadth-first - sibling nodes will be stored close to each other.
The depth-first strategy is the default indexing strategy and it is automatically created if you create an index on a column of hierarchyid data type. If your index is a clustered index, then the data will be ordered by this index.
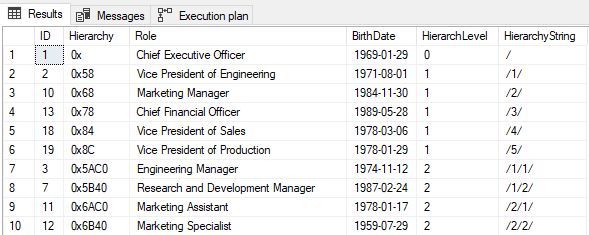
The indexed data using the depth-first strategy indexing will look like this:

Let’s see an example of creating and consuming such an index. First, we will create the appropriate index and then we will select the values using this index. When selecting the data, we will use a query hint “WITH (INDEX” that will force the engine to use the index and hopefully order the data by the desired index.
CREATE INDEX IDX_Hierarchy_DepthFirst
ON [dbo].[Hierarchy_HID](Hierarchy);
SELECT
*
, Hierarchy.ToString() AS HierarchyString
FROM
[dbo].[Hierarchy_HID] WITH (INDEX(IDX_Hierarchy_DepthFirst));
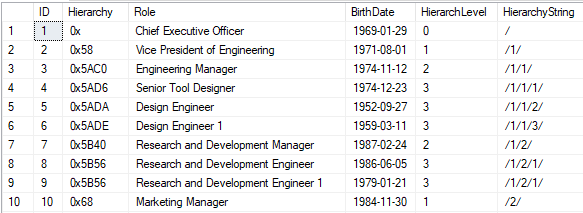
If we like to implement the breadth-first strategy, we would first need to add to our table an additional column that stores the hierarchical level of each node. This column can be also a computed column (persisted).
The indexed data using the breadth-first strategy indexing will look like this:

Let’s see an example of creating and consuming such an index.
ALTER TABLE [dbo].[Hierarchy_HID] ADD
HierarchLevel AS (Hierarchy.GetLevel()) PERSISTED;
CREATE INDEX IDX_Hierarchy_BreadthFirst
ON [dbo].[Hierarchy_HID](HierarchLevel, Hierarchy);
SELECT
*
, Hierarchy.ToString() AS HierarchyString
FROM
[dbo].[Hierarchy_HID] WITH (INDEX(IDX_Hierarchy_BreadthFirst));
Depending on your business needs you can choose the appropriate indexing strategy.
*You can download the complete SQL Script with all examples from the post here: SQL Script.sql (6.05 kb)