
Why you should use constraints on your tables? Except the fact that you should use constraints to check your data and the integrity of them (e.g. only allow inserting of numeric value between 1 and 5 for storing vote value) you could use them also for better query executions and get some performance boost. Let’s find how.
Based on [Sales].[Invoices] table from [WideWorldImporters] database we will create two tables. One containing invoice records from the current year (in the source database this is the year 2016). And the second one containing history invoices (before 2016). We will also create a SQL view aggregating this two tables. You can download the whole SQL script on the link provided at the bottom of this article.
Let’s try to select invoices for a specific date.
Example:
SELECT [InvoiceID] FROM [dbo].[Invoices] WHERE [InvoiceDate] = '2016-03-14';
/*
Table 'Invoices_History'. Scan count 1, logical reads 6835, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Invoices_Current'. Scan count 1, logical reads 1023, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
*/
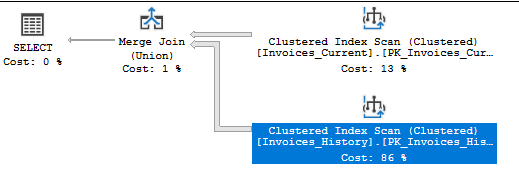
If we look at the Execution plan and to the statistics, we will notice that both tables are scanned and that we had in total almost 8000 logical reads.
Let's try to create a index on both tables on the [InvoiceDate] column and include the [InvoiceID] column. And after that let's run our query again.
Example:
CREATE NONCLUSTERED INDEX [IDX_Invoices_Current_InvoiceDate] ON [dbo].[Invoices_Current] ([InvoiceDate] ASC) INCLUDE ([InvoiceID]);
CREATE NONCLUSTERED INDEX [IDX_Invoices_History_InvoiceDate] ON [dbo].[Invoices_History] ([InvoiceDate] ASC) INCLUDE ([InvoiceID]);
GO
SELECT [InvoiceID] FROM [dbo].[Invoices] WHERE [InvoiceDate] = '2016-03-14';
/*
Table 'Invoices_History'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Invoices_Current'. Scan count 1, logical reads 158, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
*/
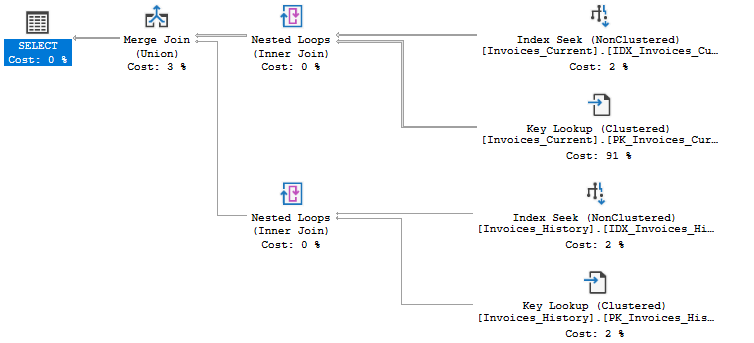
The situation is better. We have in total only 160 logical reads and the new index is used. The CPU time has considerably decreased. But, still we are looking for records in both tables. Can we do it better? Let's declare two CHECK CONSTRAINT. The first on the current table that is defined to check if the invoice date is greater or equal to the current year. And the second on the history table defining that the order date is lower than the current year. Let's see what comes out of this.
Example:
ALTER TABLE dbo.Invoices_Current ADD CONSTRAINT CK_Invoices_Current CHECK ([InvoiceDate] >= '2016-01-01');
ALTER TABLE dbo.Invoices_History ADD CONSTRAINT CK_Invoices_History CHECK ([InvoiceDate] < '2016-01-01');
GO
SELECT [InvoiceID] FROM [dbo].[Invoices] WHERE [InvoiceDate] = '2016-03-14';
/*
Table 'Invoices_Current'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
*/

As you can see, we had only 2 logical reads only on the current table! Therefore, you should use constraints.
*MS SQL Server sample database "WideWorldImporters" can be downloaded at: https://github.com/Microsoft/sql-server-samples/releases/tag/wide-world-importers-v1.0
*You can download the complete SQL Script with all examples from the post here: SQL Script.sql (2.05 kb)