
In this post we will talk about MS SQL STRING_SPLIT table-valued function introduced in MS SQL version 2016 for splitting string values by a separator, how we did it before and test its performance compared to the old way. We will also see the pros but also cons of the function.
STRING_SPLIT is pretty much the opposite from STRING_AGG described in my previous post on this blog.
As we (developers) maybe imagine/wish MS SQL STRING_SPLIT will not return us an array of spitted values (like for example the String.Split() method from C#), just because MS SQL is still table oriented more than array oriented. This is just expected and the new function STRING_SPLIT still has multiple ways of usage.
I often used it (the “old way”) as an input parameter for stored procedures and will certainly continue to use the new function in the future. Let’s try to find a hypothetically case of using split function in real life.
Imagine you have a search stored procedure for a WEB shop selling different kind of Gins. The developer of the web page can in one string parameter, comma delimited send to the stored procedure multiple properties that the user selected on the UI (e.g. ‘1,5,3’ for country of origin, bottle size etc.). This is much better than a stored procedure with @DringTypeID, @CountryOfOrigin, @BottleSize, @..., a nice example of total tuning and maintenance chaos theory. I can convert the string into “array” (or in this case a table) and with a query find all products (Gin bottles) that have all the properties from one input string parameter. This is just one example. I could find a lot of them, but this is enough, so you can get a picture of the usage. Let’s return to the function itself.
Syntax:
STRING_SPLIT (string , separator)
- String – value of any character type (nvarchar, varchar, char or nchar)
- Separator – a single character of any character type (nvarchar(1), varchar(1), nchar(1) or char(1)) that is used as separator for concatenated strings
The function returns a single-column table with parts (fragments). The name of the column is [value]. Return type depends on any of the input arguments:
- Nvarchar, nchar -> nvarchar
- All others -> varchar
Let’s see how the function is used and try to split some values.
Example:
-- Get all ingredients for a mojito cocktail
SELECT value AS "Ingredients" FROM STRING_SPLIT(N'1 1/2 oz White rum,6 leaves of Mint,Soda Water,1 oz Fresh lime juice,2 teaspoons Sugar',',');
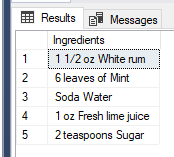
It works like a charm. What if we have two consecutive separators with no value between?
Example:
-- Get all ingredients for a mojito cocktail. There are two separators between the Mint and Soda with no text between
SELECT value AS "Ingredients" FROM STRING_SPLIT(N'1 1/2 oz White rum,6 leaves of Mint,,Soda Water,1 oz Fresh lime juice,2 teaspoons Sugar',',');
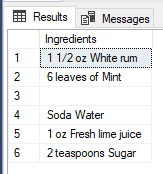
The value is a blank string. This is a expected behavior. Now, let’s try to have two separators and see what happens.
Example:
-- Split by two characters
SELECT value FROM STRING_SPLIT(N'Value 1..Value2..Value3','..');

Since the separator must be a single character an error is thrown as expected:
“Msg 214, level 16, State 11, line 12
Procedure expects parameter 'separator' of type 'nchar(1)/nvarchar(1)'.”
The table-valued function can be used not only in SELECT statement (to get results) but also in WHERE or FROM (like JOIN or CROSS APPLY). This kind of usages are the one needed for solving problems like described on the beginning of this post (stored procedure input parameter). Let’s see some examples.
First, we will use STRING_SPLIT to extract tags for every stock item. In the table [Warehouse].[StockItems] items, for every stock item there is a corresponding list of tags in JSON format:
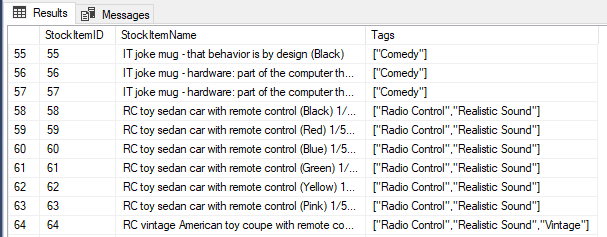
Let's see how this can be accomplished. We will use the STRING_SPLIT in the FROM part of the query using CROSS APPLY:
Example:
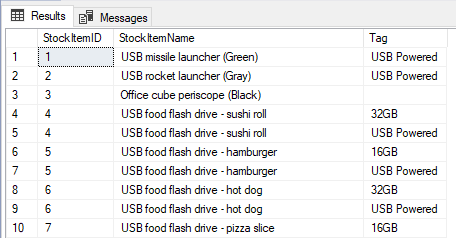
-- Get all tags for stock items
USE WideWorldImporters;
SELECT
SI.StockItemID
, SI.StockItemName
, SP.value as Tag
FROM
[Warehouse].[StockItems] SI
CROSS APPLY STRING_SPLIT(REPLACE(REPLACE(REPLACE(Tags,'[',''), ']',''), '"', ''), ',') SP;
Now we will use the STRING_SPLIT in the WHERE part of the query to get all invoices that have at least one of the stock item from the input parameter in the invoice lines.
Example:
-- Get all Invoices that have at least one of the stock items in the list (WHERE IN)
USE WideWorldImporters;
DECLARE @StockItemIDs NVARCHAR(MAX) = N'68,121,54'
SELECT
IL.InvoiceID
FROM
[Sales].[InvoiceLines] IL
WHERE
IL.StockItemID IN (SELECT CAST(value AS INT) FROM STRING_SPLIT(@StockItemIDs, ','))
GROUP BY
IL.InvoiceID
ORDER BY
IL.InvoiceID;
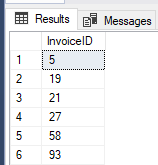
Now when we see the usage of the STRING_SPLIT function, let’s talk about performances and compare it to the "old way".
To be able to do this first we must find something that can be categorized as a “old way”. From my experience I know there are many theories, approaches and solutions to split strings in MS SQL Server before the existence of STRING_SPLIT function. The one I prefer is using XML. Maybe this is or not the optimal one, but we will not have this discussion and benchmarks about this right now. If you want to read more about different methods (and benchmarks) for splitting strings I suggest you look at this good article by Aaron Bertrand on "SQL performance.com " that you can find here.
Old way example:
SELECT * FROM [dbo].[SplitString]('Gin and tonic', ' ')
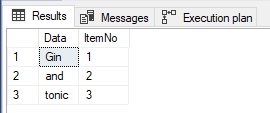
We will enable statistics, enable execution plan and discard the grid results after the execution so we can focus on pure computing power. Let’s start!
We will have 2 approaches:
- The old way using XML
- The new way using STRING_SPLIT
Example:
USE [WideWorldImporters];
SET NOCOUNT ON;
SET STATISTICS IO ON;
SET STATISTICS TIME ON;
-- Turn on statistics
-- Discard results after execution
-- Enable Execution plan
-- Create the old test function
CREATE OR ALTER FUNCTION [dbo].[SplitString] (@Data NVARCHAR(MAX), @Delimiter NVARCHAR(5))
RETURNS @Table TABLE ( Data NVARCHAR(MAX) , ItemNo INT IDENTITY(1, 1))
AS
BEGIN
DECLARE @TextXml XML;
SELECT @TextXml = CAST('<d>' + REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(@Data, '&', '&'), '<', '<'), '>', '>'), '"', '"'), '''', '''), @Delimiter, '</d><d>') + '</d>' AS XML);
INSERT INTO @Table (Data)
SELECT Data = REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(RTRIM(LTRIM(T.split.value('.', 'nvarchar(max)'))), '&', '&'), '<', '<'), '>', '>'), '"', '"'), ''', '''')
FROM @TextXml.nodes('/d') T(Split)
RETURN
END
GO
-- 1. The old way using XML
SELECT
SI.StockItemID
, SI.StockItemName
, SP.Data as Tag
FROM
[Warehouse].[StockItems] SI
CROSS APPLY [dbo].[SplitString](REPLACE(REPLACE(REPLACE(Tags,'[',''), ']',''), '"', ''), ',') SP;
-- 2. The new way using STRING_SPLIT
SELECT
SI.StockItemID
, SI.StockItemName
, SP.value as Tag
FROM
[Warehouse].[StockItems] SI
CROSS APPLY STRING_SPLIT(REPLACE(REPLACE(REPLACE(Tags,'[',''), ']',''), '"', ''), ',') SP;
Both approaches give us the same result. If you don’t believe me, you can see it by running the queries before disabling the grid results after the execution.
If we look at the execution plan we will notice some differences:
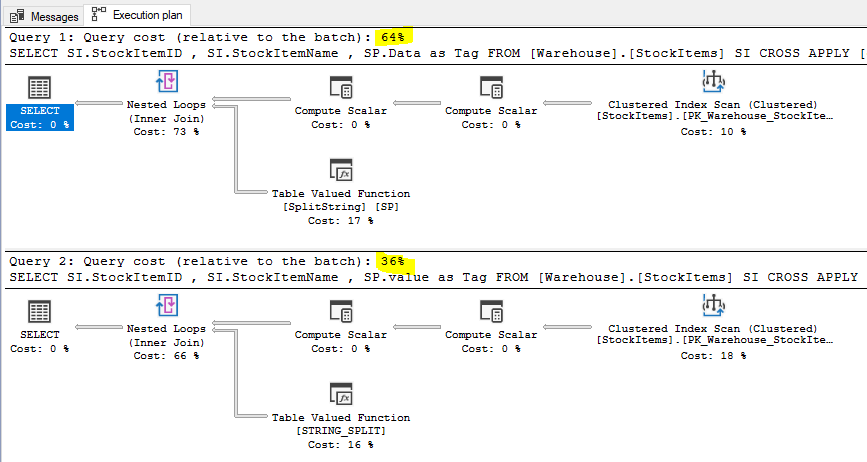
The “good old one” approach (1st) takes 64% of the query cost vs 36% to the new one (2nd). The execution plan is almost the same.
Let’s go little more in details by looking the statistics:
1st - The old way using XML
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 2 ms.
(272 rows affected)
Table '#BA2CD1B1'. Scan count 28, logical reads 227, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'StockItems'. Scan count 1, logical reads 16, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row affected)
SQL Server Execution Times:
CPU time = 31 ms, elapsed time = 45 ms.
Conclusion: The 1st approach used 31ms of CPU time with 227+ logical reads. This is the slowest one.
2nd - The new way using STRING_SPLIT
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 2 ms.
(272 rows affected)
Table 'StockItems'. Scan count 1, logical reads 16, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row affected)
SQL Server Execution Times:
CPU time = 15 ms, elapsed time = 7 ms.
Conclusion: The 2nd approach used 15ms of CPU time with only 16 logical reads. We have a winner! My conclusion is that this is the approach we should use
Hope that this mini test will suggest you why you should start to use the new MS SQL STRING_SPLIT function.
To finish, I must just point out some cons of this function:
- The function does not return the position of the element inside the input string. The “old one” with XML returns it. In most cases you will be able to live without this feature but in some cases, you will need it.
- The separator is only a single character. Also, the “old one” does accept more characters. You can do a replace of multiple characters to one (in this case you must be sure that the one is not used in the input value) or use another function for that.
- The return type is always a string, so you must cast the result if you need something else.
*MS SQL Server sample database "WideWorldImporters" can be downloaded at: https://github.com/Microsoft/sql-server-samples/releases/tag/wide-world-importers-v1.0
*You can download the complete SQL Script with all examples from the post here: SQL Script.sql (2.71 kb)