
Before MS SQL 2019 storing some characters (e.g. ASCII) in MS SQL was limited.
SQL Server supports Unicode characters in the form of nchar, nvarchar, and ntext data types that are using UTF-16 encoding. The penalty of this was that you need to pay the price for more storage and memory because you had to store all the data in Unicode (UTF-16), even when you needed only ASCII characters.
UTF-8 is the dominant character encoding system for the World Wide Web and it is used in over 90% of all web pages. UTF-8 database support allow application(s) internationalization without converting all strings to Unicode.
UTF-8 and UTF-16 both handle the same Unicode characters, and both are variable length encodings that require up to 32 bits per character. However, there are important differences that drive the choice of whether to use UTF-8 or UTF-16 in your multilingual database or column:
- UTF-8 encodes the common ASCII characters including English and numbers using 8-bits. ASCII characters (0-127) use 1 byte, code points 128 to 2047 use 2 bytes, and code points 2048 to 65535 use 3 bytes. The code points 65536 to 1114111 use 4 bytes, and represent the character range for Supplementary Characters.
- But UTF-16 uses at least 16-bits for every character in code points 0 to 65535 (available in UCS-2 and UTF-16 alike), and code points 65536 to 1114111 use the same 4 bytes as UTF-8.
UTF-8 support in MS SQL 2019 is implemented as new collations, in total there are 1.553 new collations you can chose for a database. You can identify them because they finish with the "%UTF8" suffix. You can see an example on the following image.
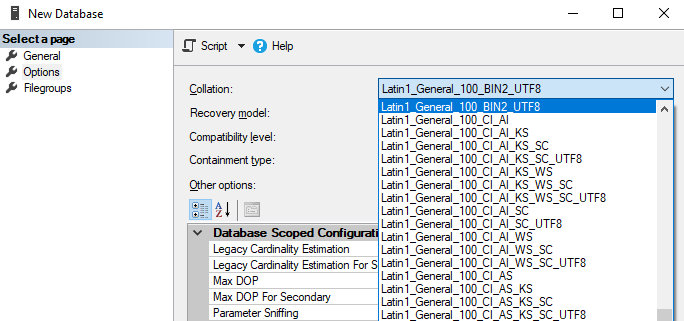
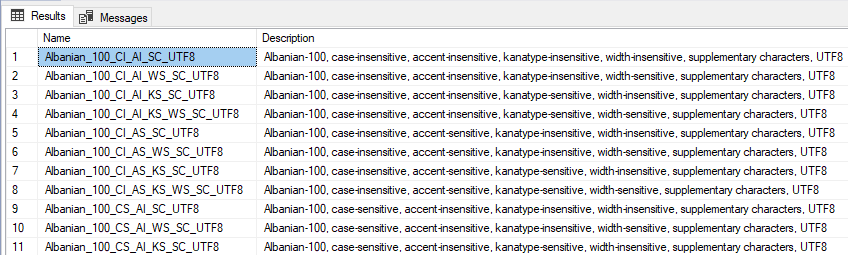
You can see all available UTF-8 collations by executing the following query:
SELECT Name, Description FROM fn_helpcollations() WHERE Name LIKE '%UTF8';
GO
Let's run the same code on two databases. The first one (named "NONUTF8") will use an old collation (Latin1_General_100_CI_AS_SC). The second database will be using a new UTF8 collation (Latin1_General_100_CI_AS_SC_UTF8). We will try to display the Russian translation for the phrase "SQL2019 supports UTF8 collation", and if Google translate does not lie to us it should sound like "SQL2019 поддерживает сопоставление UTF8".
So, the first one:
USE NONUTF8
GO
DECLARE @v VARCHAR(100) = 'SQL2019 поддерживает сопоставление UTF8';
SELECT @v AS String, DATALENGTH(@v) AS DataLengthValue;
DECLARE @nv NVARCHAR(100) = N'SQL2019 поддерживает сопоставление UTF8';
SELECT @nv AS String, DATALENGTH(@nv) AS DataLengthValue;
GO
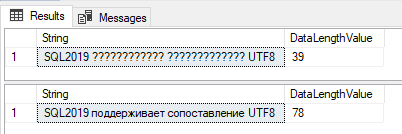
Notice that the result for the query where we are using the varchar data type is incorrect. We lose the Cyrillic characters. The characters are displayed correctly in the second query (the one with nvarchar data type).
Now, let's run the same two queries on the UTF-8 database:
USE UTF8;
GO
DECLARE @8v VARCHAR(100) = 'SQL2019 поддерживает сопоставление UTF8';
SELECT @8v AS String, DATALENGTH(@8v) AS DataLengthValue;
DECLARE @8nv NVARCHAR(100) = N'SQL2019 поддерживает сопоставление UTF8';
SELECT @8nv AS String, DATALENGTH(@8nv) AS DataLengthValue;
GO
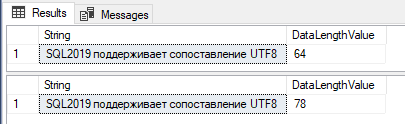
The result is now correct. We see Cyrillic characters with both data types (varchar and nvarchar).
Look also to the column "DataLengthValue". You can notice that there is a slightly improvement in the consumption of the space needed for storing Cyrillic characters using the UTF-8 encoding.
Another example using a table variable:
DECLARE @Data TABLE (
varchar_nonutf8 VARCHAR(100) COLLATE Latin1_General_100_CI_AS_SC
, varchar_utf8 VARCHAR(100) COLLATE Latin1_General_100_CI_AS_SC_UTF8
, nvarchar_nonutf8 NVARCHAR(100) COLLATE Latin1_General_100_CI_AS_SC
, nvarchar_utf8 NVARCHAR(100) COLLATE Latin1_General_100_CI_AS_SC_UTF8
);
DECLARE @Value NVARCHAR(MAX) = N'SQL2019 поддерживает сопоставление UTF8'
INSERT INTO @Data (varchar_nonutf8, varchar_utf8, nvarchar_nonutf8, nvarchar_utf8)
VALUES (@Value, @Value, @Value, @Value)
SELECT * FROM @Data

*You can download the complete SQL Script with all examples from the post here: SQL Script.sql (2.23 kb)