
There is a case when we want to get the unique number of non-NULL values in one table column.
Before MS SQL 2019 to accomplish this task, we could use the COUNT(DISTINCT([Column_Name])) syntax. For larger tables this approach can generate noticeable performance problems.
MS SQL 2019 introduced the APPROX_COUNT_DISTINCT function that approximates the count within a 2% precision to the actual value but at a fraction of the time and with noticeable decrease of used resources (memory and CPU).
If you have big tables and you can live with the approximation of the value than the APPROX_COUNT_DISTINCT function is for you. So, let’s see it in action compared to the old approach.
For this demo I will use the table [dbo].[FactOnlineSales] that has more than 12 million rows. This table can be found in the ContosoRetailDW demo database that you can find it here. Let’s count how many distinct [SalesOrderNumber] values exist using both approaches. I will turn on statistics, include actual execution plans and even save and compare them.
Example:
USE [ContosoRetailDW];
GO
SET STATISTICS TIME ON;
SET STATISTICS IO ON;
GO
SELECT COUNT(DISTINCT([SalesOrderNumber])) AS DistinctValues FROM [dbo].[FactOnlineSales];
GO
SELECT APPROX_COUNT_DISTINCT ([SalesOrderNumber]) AS DistinctValues FROM [dbo].[FactOnlineSales];
GO
First, let’s see the result.
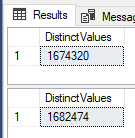
1.674.320 compared to 1.682.474, the difference of exactly 8.154 "values" or in percentage of 0,49%. APPROX_COUNT_DISTINCT returned 0,49% greater value than the actual number of distinct values.
Now let’s compare the CPU time of these two queries:
COUNT(DISTINCT([SalesOrderNumber])) -> CPU time = 12486 ms, elapsed time = 12588 ms
APPROX_COUNT_DISTINCT([SalesOrderNumber]) -> CPU time = 7819 ms, elapsed time = 7827 ms
Conclusion, COUNT(DISTINCT… used 61% more CPU time than the brand new APPROX_COUNT_DISTINCT. Seems like 8 seconds compared to the 12 second’s isn’t really a big deal. Is it worth to sacrifice precision to gain some time? Maybe you are thinking: “if I can wait 8 seconds probably I could wait 4 seconds more to get the correct value”. But we are not yet finished.
Let’s finally compare the execution plans of these two queries.
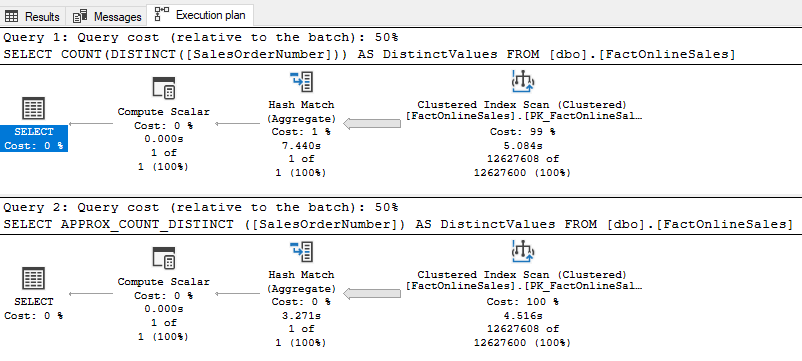
Seams like the execution plans are identical. Both queries used 50% of the whole query. This is because both queries had 43.944 logical reads. But where is the difference? Look here:
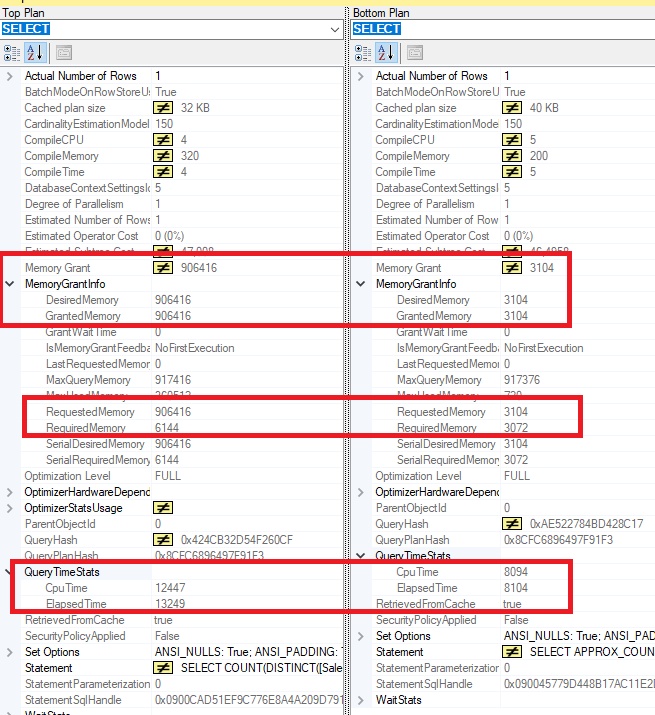
The first query required 906.416 KB of memory !?!!? That's more than 885 MB. The second one used only 3.104 KB or 3 MB of memory. In this case this was the greatest benefit of using APPROX_COUNT_DISTINCT function.
In some scenarios you will not dramatically benefit when using the APPROX_COUNT_DISTINCT function. I sow some articles online that doubt about the benefits of its usage. But I as most of other authors agree that the APPROX_COUNT_DISTINCT function substantially reduces memory footprint. This means that much larger number of users could run the same query simultaneously on a system without any noticeable performance degradation. The point is not always to run something faster. The idea is to sometimes run things with less resources.