
In this post we will learn something about MS SQL STRING_AGG function introduced in MS SQL version 2017 for string aggregation, how we did it before and test its performance compared to the old way.
STRING_AGG is pretty much the opposite from STRING_SPLIT described in another post on this blog that you can find here.
Syntax:
STRING_AGG (expression, separator) [<order_clause>]
- Expression - Is an expression of any type. Expressions are converted to NVARCHAR or VARCHAR types during concatenation. Non-string types are converted to NVARCHAR type. It is usually a column name.
- Separator - string of NVARCHAR or VARCHAR type that is used as separator for concatenated strings. It can be literal or variable. It has a maximum size of 8,000 bytes.
- Order_clauese - Optionally specify order of concatenated results by using WITHIN GROUP clause
The function returns a string, but the exact return type depends on the input string expression (1st argument):
- int, bigint, smallint, tinyint, numeric, float, decimal, datetime… -> nvarchar (4000)
- nvarchar -> nvarchar (4000)
- varchar -> varchar (8000)
- nvarchar (MAX) -> nvarchar (MAX)
Let’s see how the function is used and try to aggregate some values.
Example:
-- Aggregate values
SELECT STRING_AGG(value, ' ') AS Result FROM (VALUES('Gin'),('and'),('tonic')) AS I(value);
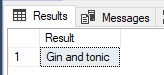
Let’s make another example using a real database data. We will aggregate all customer names from the customer table.
Example:
USE [WideWorldImporters];
-- Aggregate customer names
SELECT STRING_AGG(C.[CustomerName], ',') AS Result FROM [Sales].[Customers] AS C;

The result is an error:
“Msg 9829, level 16, State 1, line 6
STRING_AGG aggregation result exceeded the limit of 8000 bytes. Use LOB types to avoid result truncation.”
The reason for that is that the CustomerName column is of type nvarchar(100) and based on the return type for nvarchar data type is nvarchar(4000). We must cast the expression (1st) parameter to nvarchar(max) to make it work.
Example:
-- Aggregate customer names
SELECT STRING_AGG(CAST(C.[CustomerName] AS nvarchar(max)), ',') AS Result FROM [Sales].[Customers] AS C;

Nice, this is exactly what we want to accomplish.
Let’s find out how STRING_AGG handles NULL values.
Example:
-- Aggregate NULL values
SELECT STRING_AGG(value, ' ') AS Result FROM (VALUES('Gin'),(NULL),('tonic')) AS I(value);
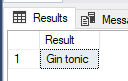
The result is not so bad 😊. NULL values are represented by an empty string. If you want to show the NULL value in the output string you must use ISNULL or COALESCE functions.
The next task is to try to group results by some key. Let’s try to get delimited all invoiceIDs for every customerID in the table [Sales].[Invoices].
Example:
USE [WideWorldImporters];
-- delimited invoiceID for every customerID in the table
SELECT
[CustomerID]
, STRING_AGG([InvoiceID], ',') AS InvoicesList
FROM
[Sales].[Invoices] I
GROUP BY
[CustomerID]
ORDER BY
[CustomerID] ASC;
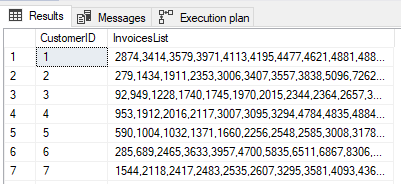
The result is here but we have no guarantee how the InoviceIDs are sorted. If we want to sort them (and be sure they are sorted) we must use the WITHIN GROUP clause. Let’s see how it work.
Example:
USE [WideWorldImporters];
-- delimited and sorted invoiceID for every customerID in the table
SELECT
[CustomerID]
, STRING_AGG([InvoiceID], ',') WITHIN GROUP(ORDER BY [InvoiceID] ASC) AS InvoicesList
FROM
[Sales].[Invoices] I
GROUP BY
[CustomerID]
ORDER BY
[CustomerID] ASC;
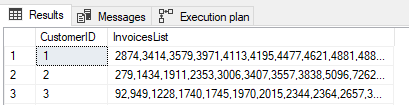
Using the WITHIN GROUP clause assure as that the invoices are sorted.
Now, let’s talk about performances of the MS SQL STRING_AGG function and compare it to the "old way".
To be able to do this first we must find something that can be categorized as a “old way”. From my experience I know there are many theories, approaches and solutions to aggregate data in MS SQL Server before the existence of STRING_AGG function. The one I prefer is using XML with STUFF. Maybe this is or not the optimal one, but we will not have this discussion and benchmarks about this right now. If you want to read more about different row concatenation methods I suggest you look at this good article by Anith Sen on "Redgate Simple Talk" that you can find here. Since STRING_AGG is working nice i will try to forget all the “old ways” 😊.
We will enable statistics, enable execution plan and discard the grid results after the execution so we can focus on pure computing power. Let’s start!
We will have 3 approaches:
- The old way using XML and STUFF
- The new way using STRING_AGG for aggregation inside sub select (like the old way)
- The new way using STRING_AGG with no sub select
Example:
USE [WideWorldImporters];
SET NOCOUNT ON;
SET STATISTICS IO ON;
SET STATISTICS TIME ON;
-- Turn on statistics
-- Discard results after execution
-- Enable Execution plan
-- 1. The old way using XML and STUFF
SELECT
C.[CustomerID]
, STUFF((
SELECT
',' + CAST(I.[InvoiceID] AS NVARCHAR(MAX))
FROM
[Sales].[Invoices] I
WHERE
I.[CustomerID] = C.[CustomerID]
ORDER BY
I.[InvoiceID] ASC
FOR XML PATH(''), TYPE).value('.', 'varchar(max)'),1,1,'') AS InvoicesList
FROM
[Sales].[Customers] AS C
ORDER BY
C.[CustomerID] ASC;
-- 2. The new way using STRING_AGG for aggregation inside sub select (simmilar to the old way)
SELECT
C.[CustomerID]
, (
SELECT
STRING_AGG([InvoiceID], ',') WITHIN GROUP(ORDER BY [InvoiceID] ASC) AS InvoicesList
FROM
[Sales].[Invoices] I
WHERE
I.[CustomerID] = C.[CustomerID]
)
FROM
[Sales].[Customers] AS C
ORDER BY
C.[CustomerID] ASC;
-- 3. The new way using STRING_AGG with no sub select
SELECT
[CustomerID]
, STRING_AGG([InvoiceID], ',') WITHIN GROUP(ORDER BY [InvoiceID] ASC) AS InvoicesList
FROM
[Sales].[Invoices] I
GROUP BY
[CustomerID]
ORDER BY
[CustomerID] ASC;
All three approaches give us the same result. If you don’t believe me, you can see it by running the queries before disabling the grid results after the execution.
If we look at the execution plan (not in detail) the first thing we will notice is:
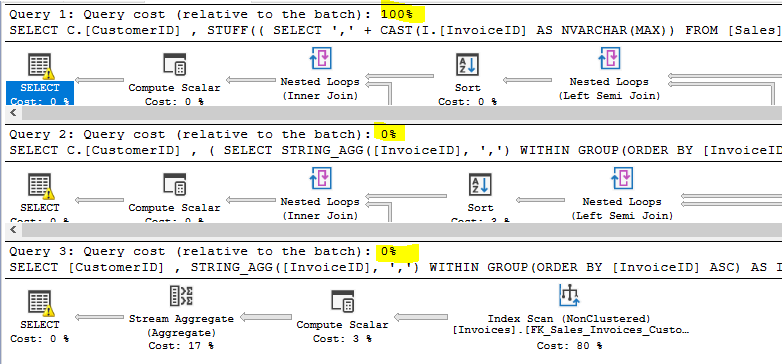
The “good old one” approach (1st) takes almost the complete query cost of the entire execution.
Let’s go little more in details by looking the statistics:
1st - The old way using XML and STUFF
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 16 ms, elapsed time = 26 ms.
Table 'Invoices'. Scan count 663, logical reads 1514, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Customers'. Scan count 1, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 140 ms, elapsed time = 155 ms.
Conclusion: The 1st approach used 140ms of CPU time with 1512+ logical reads. This is the slowest one of all three approaches tested.
2nd - The new way using STRING_AGG for aggregation inside sub select (like the old way)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 15 ms, elapsed time = 23 ms.
Table 'Invoices'. Scan count 663, logical reads 1614, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Customers'. Scan count 1, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 31 ms, elapsed time = 38 ms.
Conclusion: Interesting the 2nd approach had more logical reads (1614+) but used only 31ms of CPU time.
3rd - The new way using STRING_AGG with no sub select
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 3 ms.
Table 'Invoices'. Scan count 1, logical reads 166, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 31 ms, elapsed time = 35 ms.
Conclusion: And finally, the winner, the 3rd one had only 166 logical reads. The CPU time is quite the same as the 2nd but based on logical reads my conclusion is that this one is the one we should use.
I am aware that the 3rd one will probably win because it uses only one table and has no sub select like the first two. But the first two shows us the real benefit of using or not using STRING_AGG function.
Hope you liked this post.
*MS SQL Server sample database "WideWorldImporters" can be downloaded at: https://github.com/Microsoft/sql-server-samples/releases/tag/wide-world-importers-v1.0
*You can download the complete SQL Script with all examples from the post here: SQL Script.sql (2.59 kb)